Understanding Bayes's Rule Through a Concrete Example
2024-01-17
Understanding Bayes’s Rule Through a Concrete Example
Bayes’s rule is a fundamental concept in probability theory, offering a robust framework for understanding conditional probabilities. This article delves into Bayes’s rule, illustrating its principles through a practical example and visualizations. The example is taken from Example 1.10.1 (Page 59 - 62) of the book An Introduction to Kolmogorov Complexity and Its Application, Fourth Edition, authored by Ming Li and Paul Vitányi.
Formal Statement of Bayes’s Rule
Bayes’s rule can be formally stated as follows:
$$ P(A | B) = \frac{P(B | A)P(A)}{P(B)} $$
where:
- $P(A | B)$ is the posterior probability of event $A$ given event $B$.
- $P(B | A)$ is the likelihood of event $B$ given event $A$.
- $P(A)$ is the prior probability of event $A$.
- $P(B)$ is the marginal probability of event $B$.
Illustrative Example: The Dice Urn
Consider an urn filled with dice, each having a unique probability $p$ of showing the number 6. The probability $p$ may differ from the 1 / 6 expected from a fair die. If we draw a die from the urn and roll it $n$ times, observing the number 6 $m$ times, we can use Bayes’s rule to understand the probabilities involved.
Prior Distribution
Let $P(X=p)$ represent the prior probability of drawing a die with probability $p$ of showing a 6. According to von Mises’s interpretation, the relative frequency of drawing a die with a specific $p$ converges to $P(X=p)$ over many draws.
Likelihood Function
The likelihood of observing $m$ outcomes of 6 in $n$ throws for a die with probability $p$ is given by the binomial distribution:
$$ P(Y=m | n, p) = \binom{n}{m} p ^ m(1 - p) ^ {n - m} $$
This represents the number of ways to choose $m$ successful outcomes from $n$ trials, multiplied by the likelihood of those successes and failures.
Posterior Distribution
Therefore, the probability of drawing a die with probability $p$ and subsequently observing $m$ outcomes of 6 in $n$ throws is the product $P(X=p)P(Y=m | n, p)$.
In this context, Bayes’s problem involves determining the probability of observing $m$ outcomes of 6 in $n$ throws due to a die with a specific probability $p$. The solution is given by the posterior or inferred probability distribution:
$$ P(X=p | n, m) = \frac{P(X=p)P(Y=m | n, p)}{\sum_{p} P(X=p)P(Y=m | n, p)} $$
Here, the denominator is the sum over all possible values of $p$, ensuring the probabilities sum to 1.
Experiments and Visualization
To understand these concepts better, let’s conduct a series of experiments and visualize the results.
Experiment 1: Uniform Prior
Let $p$ take values 0.1, 0.2, …, 0.9, each with equal probability $P(X=p) = 1 / 9$. We consider two cases: $n = 5, m = 3$ and $n = 500, m = 300$.
Case 1: $n=5, m=3$
Case 2: $n=500, m=300$
Experiment 2: Weighted Prior
Let the new prior distribution be $P(X=p) = i / 45, i = 1, …, 9$. We analyze the inferred probabilities for the same two cases.
Case 1: $n=5, m=3$
Case 2: $n=500, m=300$
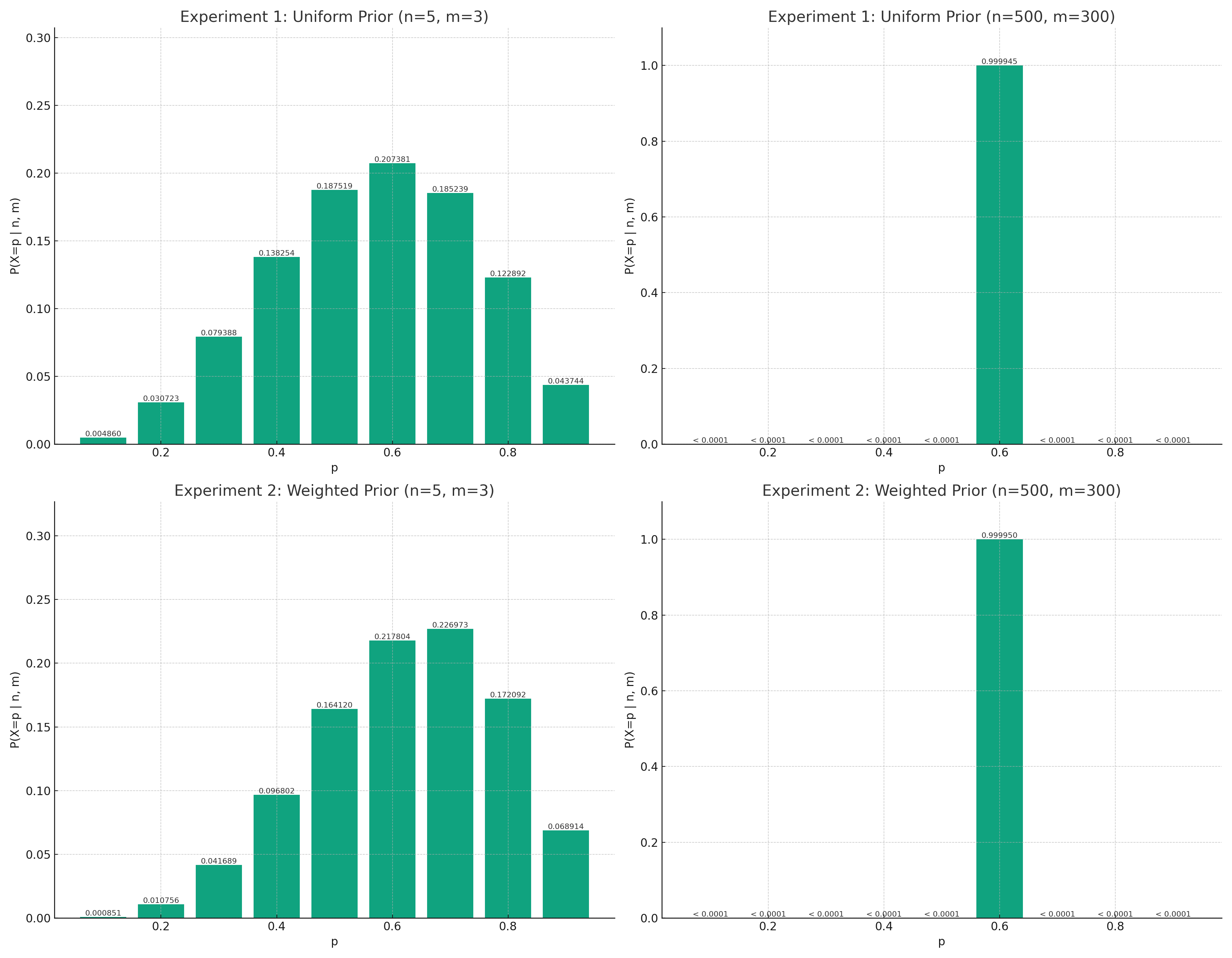
These experiments demonstrate that as the number of trials increases, the limiting value of the observed relative frequency of success approaches the true probability of success, regardless of the initial prior distribution. Bayes’s rule proves to be a powerful tool for making inferences based on a large number of observations. However, for small sequences of observations, knowledge of the initial probability is crucial for making justified inferences.
The codes for the experiments are generated by ChatGPT.
|
|
Conclusion
This approach quantifies the intuition that when the number of trials $n$ is small, the inferred distribution $P(X=p | n, m)$ heavily depends on the prior distribution $P(X=p)$. However, as $n$ increases, the inferred probability $P(X=p | n, m)$ increasingly concentrates around the empirical frequency $m / n = p$, regardless of the prior.